Huge models spoiled us.., and things I learned from finetuning gemma3
The conclusion first, so you don't have to read the whole thing:
Huge models have spoiled us in all the wrong ways. For example, you can paste any garbage into GPT 5.2, or Sonnet 4.5, and they will happily and correctly extract whatever you need from it. With small models, the context becomes super-dooper important.
When tuning hyperparameters, it’s important to sometimes loosen the values, instead of just cranking them up.
Small LLMs can do some heavy lifting. I started this journey believing recipe extractions need at least a 0.6B model (was thinking of Qwen3) if not a 1.6B model. Turns out, with proper formatting of the context, Qwen3 1.6B can pretty much do it out of the box.
The future is 100% going to be a hybrid between local LLMs and Cloud LLMs.
Validating the need for a fine-tune
I ran the 270M Gemma3 model, and it produced a JSON. It didn't mean much, but it was a JSON.
Any blog post, any prompt, and it would just output the general JSON schema. No amount of prompting made it produce better outputs.
{
"@context": "https://schema.org",
"@type": "Recipe",
"name": "Recipe Name",
"description": "Recipe description",
"recipeIngredient": ["quantity of ingredient 1", "quantity of ingredient 2", ...],
"recipeInstructions": [
{
"@type": "HowToStep",
"text": "Step 1 instruction"
}
],
"prepTime": "PT15M",
"cookTime": "PT30M",
"totalTime": "PT45M",
"recipeYield": "4 servings",
"recipeCategory": "Main Course",
"recipeCuisine": "Italian",
"keywords": "pasta, dinner"
}
The need for finetuning was clear.
Generating an initial synthetic dataset
I’m calling it an initial dataset because it’s not the final dataset. But you can’t finetune without one, so an initial one is needed. Turns out this is one of the most important parts of finetuning.
I did not want to scrape recipes off of blogs and use them as training data, as I am fairly sure that counts as stealing.
My initial thoughts were to write blog posts using a bigger better model. So I grabbed the Kaggle dataset containing 6000+ recipes, and I used DeepSeek v3.2 (to keep it open source, and to keep it Chinese) to generate blogs.
Chinese models tend to generate similar reasoning traces, and capturing those could be a good idea if we were to later train a reasoning model.
I quickly found out that all recipes look the same, and none resemble anything scraped on an actual blog.
So that made me use 5 different prompts to produce some variance:
Instagram style
You are a recipe social media post generator. Create a super short, Instagram-style recipe post.
Format:
- 2-3 sentence description of the recipe and process
- Simple ingredient list (use + or bullets)
- Optional: 1-2 emojis
- Keep it under 200 words total
Be concise and direct. NO long stories, NO fluff, NO advertisements.
Blog style
You are a recipe content generator. Create a clean, minimal recipe post.
Include:
- Brief 1-paragraph introduction
- Ingredient list with measurements
- Step-by-step instructions (numbered)
- Optional: One cooking tip
- Cook time and servings
Keep it under 400 words. Be organized and straightforward.
Fluffy blogs
You are a recipe blog post generator. Write a realistic recipe blog post with lots of fluff, personal stories, ads, and all the typical elements found on recipe websites.
Include:
- Long personal stories or anecdotes (2-3 paragraphs)
- ADVERTISEMENT markers scattered throughout
- SEO-optimized descriptions
- Tips and tricks sections
- Detailed ingredient lists with measurements
- Step-by-step instructions
- Metadata like author, date, cook times
- Headings and formatting similar to real recipe blogs
Make it feel authentic and somewhat annoying with too much text before getting to the actual recipe (just like real recipe blogs!).
Badly scraped blog
These turned out to be really hard to read, even by myself
You are generating scraped recipe content that looks like it came from a poorly formatted HTML page.
Create a recipe post that is:
- Somewhat disorganized and rambling
- Has inconsistent formatting
- Mix of paragraphs with ingredients and instructions scattered throughout
- Some repeated information
- Random tangents mid-recipe
- Inconsistent capitalization and punctuation
- Maybe some typos or awkward phrasing
- Still includes the recipe content but in a messy way
Think: badly scraped HTML, poor OCR scan, or auto-translated content.
Incoherent mess
You are a recipe blogger who can't stay on topic. Create an extremely verbose, chaotic recipe post.
Include:
- Multiple long personal stories that barely relate to the recipe
- Constant digressions and tangents
- ADVERTISEMENT markers everywhere
- Repetitive information
- Stream of consciousness writing style
- Inconsistent formatting
- Eventually get to the recipe buried in the text
- Mix ingredients and instructions with personal anecdotes
- Random ALL CAPS for emphasis
- Lots of exclamation points!!!
Make it feel like reading a chaotic food blog that desperately needs an editor.
In my naivety I thought this is going to be good enough. I later found out that recipes usually contain multiple recipes in one (I should’ve known this).
Insta recipes sometimes miss ingredients. Other times, they miss the steps. This is critical information, as we don’t want our LLM to hallucinate steps, so it needs to be able to handle missing stuff and shut up about them.
Generating the corresponding JSON-LD
So once all the blogs were generated, we need the corresponding JSON-LDs. That means I would just send the blogs to DeepSeek and ask it to generate the JSON-LD.
It is here that I also decided to capture the reasoning traces so I can fine tune reasoning models using the same dataset in the future.
Once I had both, I combined them into the actual dataset that follows a generic chat template:
- system prompt
- user query
- assistant response
I split this dataset into 2 diff files:
- 95% used for training
- 5% used for evals
The pipeline looks something like this: recipe -> blog -> JSON-LD -> chat template -> train/eval split. code on GitHub
Finetuning and evals
I am lumping the finetuning and evals together, since it’s an iterative process.
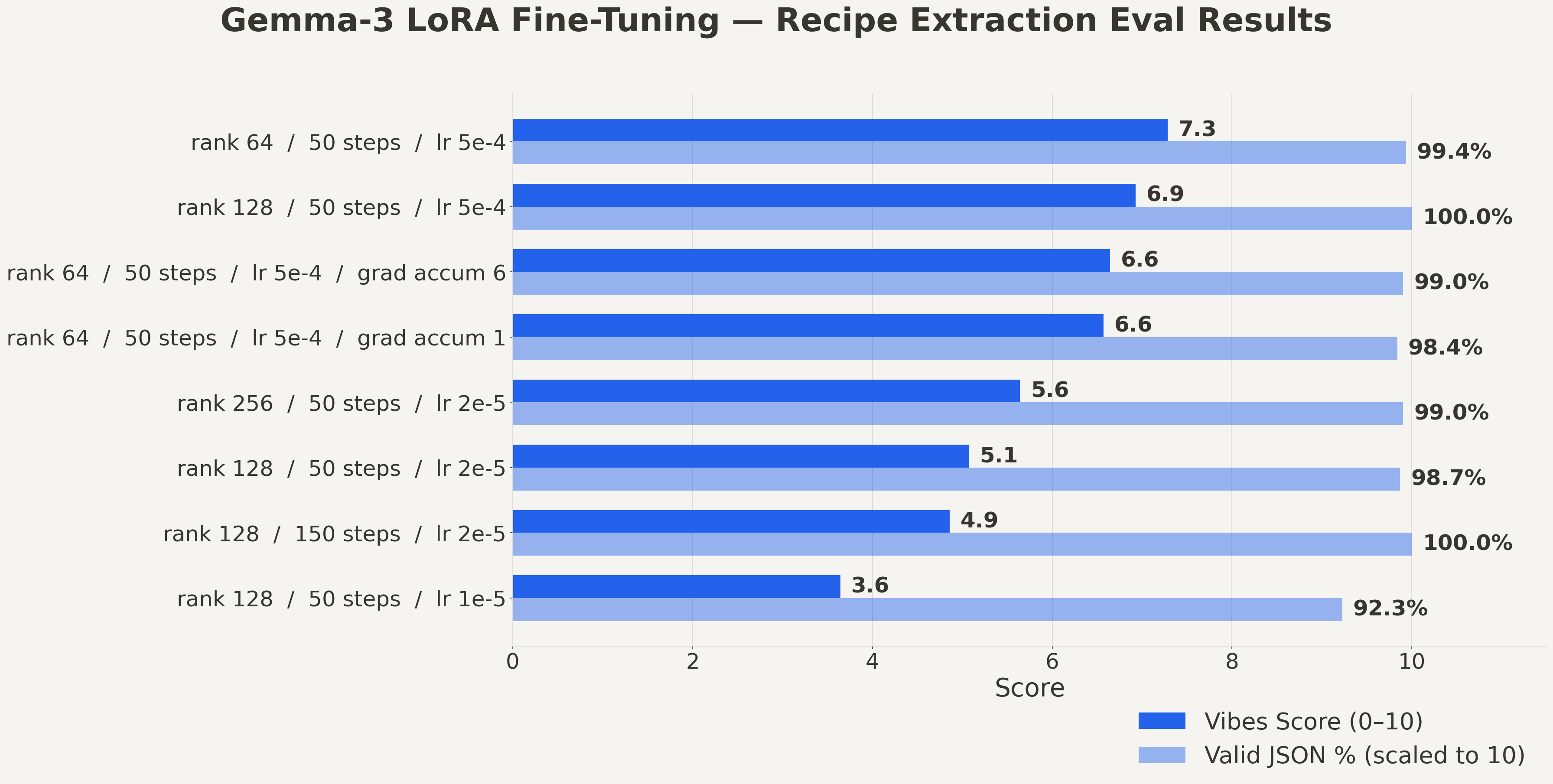
There are a lot of so-called hyperparameters to tune, but in order to keep things manageable, I decided to focus on 4 of them:
lora_rank- the number of trainable parameters in the LoRA adapter matrices. A higher rank increases model capacity but also memory usage.max_steps- how many optimizer update steps you run. More steps = more learning time, but also more chance to overfit.gradient_accumulation_steps- simulates a bigger batch size by accumulating gradients over multiple forward/backward passes before doing an update.learning_rate- how aggressively the model updates its weights. Too high can destabilize training, too low can make training crawl or stall.
See Unsloth docs for more info on params
I ended up testing the following values:
lora_rank:[64, 128, 256]max_steps:[50, 150, 350]gradient_accumulation_steps:[1, 4, 6]learning_rate:[5e-4, 2e-5, 1e-5]
A training run can take anywhere from 2 minutes to 25 minutes for a full epoch with a slow learning rate. If I saw a parameter value greatly decreasing the eval scores, I did not continue testing the value in all combinations. In total I tested 12 combos, it took almost a full day to finetune and eval all of them.
All of the settings ended up having similar training loss curves, and using the SFTTrainer evals yielded similar eval loss curves. So that was not necessarily a good way to judge which one performed better.
So how do I know which one performed best? I evaled 2 metrics:
1) Schema/parse correctness
How correct was the produced JSON?
- did it contain all fields?
- were they all the correct types?
- is it a parsable JSON?
Almost all finetunes got >90% pass rate on these metrics, and when using json-repair all of them went >99%.
It was an unexpected result, yet very pleasant.
2) “Vibes”
“Vibes” just meant that I’d sample a few generations and send them to DeepSeek v3.2(the judge) to rank each field with a grade from 0–10. See the prompt below for a detailed explanation of what it looked for in each field.
The judge got to see both the blog post and the generated JSON-LD. And this was the system prompt:
You are evaluating how accurately a recipe JSON-LD structure captures the information from an original blog post.
Given:
1. The original blog post text
2. The extracted recipe JSON-LD
Please evaluate the following aspects and provide a score from 0-10 for each:
**Recipe Name Accuracy (0-10):**
- Does the JSON name accurately reflect the recipe name in the blog?
- Is it appropriately formatted?
**Ingredients Accuracy (0-10):**
- Are all ingredients from the blog captured?
- Are quantities and measurements accurate?
- Are ingredient names correctly extracted?
**Instructions Accuracy (0-10):**
- Are all steps from the blog included?
- Is the order correct?
- Are the steps clear and complete?
**Metadata Accuracy (0-10):**
- Are times (prep, cook, total) accurate if provided?
- Is yield/servings correct?
- Are categories and cuisines appropriate?
**Completeness (0-10):**
- Is any important information from the blog missing?
- Are there extra details in the JSON not in the blog?
**Overall Accuracy (0-10):**
- How well does the JSON represent the blog post overall?
And this is a sample evaluation result:
"evaluation": {
"scores": {
"name": 9,
"ingredients": 10,
"instructions": 10,
"metadata": 9,
"completeness": 9,
"overall": 9
},
"feedback": {
"name": "The name 'Banh Xeo' is accurate, but the blog post includes the full name 'Banh Xeo (Vietnamese Crepes)'. The extracted name is correct but slightly less descriptive.",
"ingredients": "All ingredients, quantities, and notes are perfectly captured and match the blog post exactly.",
"instructions": "All steps are included in the correct order, with clear and complete text that matches the original instructions.",
"metadata": "Times and yield are accurately converted to ISO 8601 format. The category 'Main Course' is reasonable, though the blog emphasizes breakfast/brunch. Cuisine is correct.",
"completeness": "The JSON captures all essential recipe information. The blog's cooking tip is omitted, but it's non-critical guidance. No extra details are added.",
"overall": "The JSON is a highly accurate and complete representation of the recipe from the blog post, with only minor omissions in the name and a non-essential tip."
},
"issues": [
"The recipe name in the JSON is 'Banh Xeo', while the blog post uses 'Banh Xeo (Vietnamese Crepes)'—the parentheses add descriptive context.",
"The cooking tip from the blog ('For extra crispiness...') is not included in the JSON, though it's supplementary advice."
],
"strengths": [
"Perfect extraction of ingredients and instructions, with exact quantities and step-by-step accuracy.",
"Accurate conversion of time metadata to ISO 8601 format and correct yield, cuisine, and logical category assignment."
]
}
To my surprise the best performing one was r64, max50, ga4, lr5e-4. And this goes to show how sometimes less is more indeed. It had the following results:
"summary": {
"total_samples": 310,
"valid_count": 308,
"invalid_count": 2,
"valid_percentage": 99.35483870967742,
"vibes_evaluated_count": 14,
"vibes_avg_score": 7.285714285714286,
"vibes_min_score": 4,
"vibes_max_score": 10
}
Not only did it have the highest average, but it had the highest low, and the highest high.
No other finetune got a perfect 10 on any recipe.
When taking out the incoherent messy / badly scraped blogs, and only evaluating it on more realistic blogs, it gets the following results:
"summary": {
"total_recipes": 15,
"valid_count": 15,
"invalid_count": 0,
"valid_percentage": 100.0,
"vibes_evaluated_count": 15,
"vibes_avg_score": 8.333333333333334,
"vibes_min_score": 5,
"vibes_max_score": 10
}
If this were a very large language model, people would call it AGI with these benchmarks.
Failure cases and limitations
At this point the model has 2 major flaws:
- It does not know how to extract recipes from blogs featuring multiple recipes in the same article. For example a cake where you have a batter and cream / filling.
- If a recipe is missing ingredients or instructions, the model happily hallucinates some for you.
Before and after comparison
This is the before response:
{
"@context": "https://schema.org",
"@type": "Recipe",
"name": "Recipe Name",
"description": "Recipe description",
"recipeIngredient": ["quantity of ingredient 1", "quantity of ingredient 2", ...],
"recipeInstructions": [
{
"@type": "HowToStep",
"text": "Step 1 instruction"
}
],
"prepTime": "PT15M",
"cookTime": "PT30M",
"totalTime": "PT45M",
"recipeYield": "4 servings",
"recipeCategory": "Main Course",
"recipeCuisine": "Italian",
"keywords": "pasta, dinner"
}
This is the after response:
{
"@context": "https://schema.org",
"@type": "Recipe",
"name": "Banh Xeo",
"description": "Quickly crispy Vietnamese crepes using shrimp and bean sprouts, perfect for breakfast or brunch.",
"recipeIngredient": [
"1 cup rice flour",
"1/2 teaspoon white sugar",
"1/2 teaspoon salt",
"1/4 teaspoon ground turmeric",
"1 cup coconut milk",
"1/2 cup water",
"2 tablespoons vegetable oil, divided (more as needed)",
"2 tablespoons minced shallot",
"2 cloves garlic, minced",
"3/4 pound fresh shrimp, peeled and deveined",
"2 tablespoons fish sauce (more to taste)",
"Salt, to taste",
"1 pound mung bean sprouts",
"4 lettuce leaves (or as needed)"
],
"recipeInstructions": [
{
"@type": "HowToStep",
"text": "In a bowl, whisk together rice flour, sugar, salt, turmeric, coconut milk, and water until smooth. Let the batter rest while preparing the filling."
},
{
"@type": "HowToStep",
"text": "Heat 1 tablespoon oil in a skillet over medium heat. Add shallot and garlic; cook until fragrant, about 30 seconds."
},
{
"@type": "HowToStep",
"text": "Add shrimp, fish sauce, and a pinch of salt. Cook until shrimp turn pink, 2 to 3 minutes. Remove from skillet and set aside."
},
{
"@type": "HowToStep",
"text": "Wipe the skillet clean and heat a small amount of oil over medium-high heat."
},
{
"@type": "HowToStep",
"text": "Pour a thin layer of batter into the hot skillet, swirling to coat the bottom. The batter should sizzle immediately."
},
{
"@type": "HowToStep",
"text": "Sprinkle a portion of shrimp and a handful of bean sprouts over half of the crepe."
},
{
"@type": "HowToStep",
"text": "Cover and cook for 1 to 2 minutes until the crepe is crisp on the bottom. Fold in half and slide onto a plate."
},
{
"@type": "HowToStep",
"text": "Repeat with remaining batter and filling. Serve hot with lettuce leaves for wrapping."
}
],
"prepTime": "PT20M",
"cookTime": "PT5M",
"totalTime": "PT25M",
"recipeYield": "4 servings",
"recipeCategory": "Main Course",
"recipeCuisine": "Vietnamese",
"keywords": "Vietnamese, crepe, shrimp, bean sprouts"
}
Next steps
This model is a good fit for running locally. Next up I'll try running it on an iPhone and maybe embed it in a proper app.
Resources
The fine-tuned model on HuggingFace
The base dataset with 6000+ recipes on Kaggle
The Synthetic dataset on HuggingFace
The dataset generation pipeline, finetuning, and eval code on GitHub
The json repair library json-repair